Okay, this is another one of those linux newbie posts where I tried to figure out how to do something that’s probably really obvious to all you seasoned hackers out there.
Anyway here I go clogging up the internet with a post that somebody, somewhere will hopefully find useful.
Are you that person? Well… have you ever used the shell command curl to fetch a web page? It’s cool, isn’t it, but you do end up with a splurge of ugly HTML tags in your terminal shell:

Eugh!
So… how about we parse that HTML into something human-readable?
Enter my new friend, w3m, the command-shell web browser!
If you’re using OS X, you can install w3m using darwinports thusly:
sudo port install w3m
Linux hackers, I’m going to assume you can figure this out for yourselves.
So, with a brand-new blade in our swiss-army knife, let’s pipe the curl command into the standard input for w3m and see what happens:
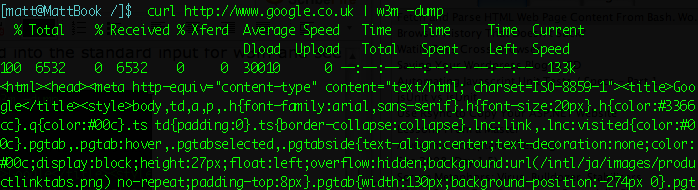
Hmm… two problems here: because I’ve grabbed its output and piped it off to w3m, curl has started blethering on about how long it took. I can fix that with swift but ruthless the flick of a -s switch to silence it. How about all that raw HTML though – I thought this w3m thing was supposed to parse my html, not just regurgitate it?
It turns out that w3m assumes its input is of MIME-type text/plain, unless told otherwise. Let’s set the record straight:

Aw yeah. Now we’re talking. Old-skool green-screen meets nu-school interweb. It’s like being back on the BBS network of yore.
What’s the point of all this? Well, that’s up to you. I have a couple of ideas, but you’re going to have to start coming up with your own you know. Why are you reading this anyway? Haven’t you got anything better to do?
Awesome sauce thanks buddy 🙂
Well there are a few things you can do with with curl, w3m, html2text
Currently I have a few things in my bag o’ scripts:
1) Command line wikipedia script
2) Zipcode look up script
3) NPA IE: Area code lookup script (telco thing)
4) NPA-NXX Area code and prefix lookup script. (telco thing)
5) NPA-NXX-XXXX phone number lookup script. (telco thing).
6) Dictionary lookup script using curl. Since curl understands the dict protocol.
5) acronyms lookup script (curl again)
6) soundslike script that looks words up in the soundex database (helps for misspelled words that your word processor or text editor doesn’t catch.
Ahhhh what the heck; here is the windows version of curl with the dictionary script:
curl -s dict://dict.org/d:%1:gcide &
curl. -s dict://dict.org/d:%1:wn &
curl. -s dict://dict.org/d:%1:web1913 &
Replace the %1 on windows to a $1 in OSX, Linux, BSD, Solaris and your golden.
Here is the scripts for the soundex database (IE: word sounds like):
curl.-s dict://dict.org/m:%1::soundex
curl. -s dict://dict.org/m:%1::soundex:1
Script for a thesaurus
curl. -s dict://dict.org/d:%1:moby-thes
check out dict.org for the protocol and a list of database that they have accessible to the public.
Here is the script for the wiktionary look up script. Check out the database to see what other data formats can be outputted. Text, html, etc. Wikitionary is dictionary side of the house of Wikipedia. They are making a free dictionary.
curl. -s dict://dict.hewgill.com/d:%1:en-brief &
curl –manual | grep dict
Don’t forget to read the RFC on the dict protocol.
I would post the others but those scripts are quite long and their on my nix boxes.
PS: You can use the dump option in w3m and look into the column option . On a related note; check out “html2text”
Options -ascii -style pretty
html2text is part curl and part w3m. More options exist when using curl and html2text, than html2text alone.
PSS: Good luck on your job search.
Regards.
Geez… my formatting is horrible…
On the *nix boxes… I got the scripts combined… Windows…. well… uhhh…. batch files have lost their appeal many moon’s ago.
Great stuff! I have to admit I wasn’t aware of curl before. However I couldn’t track down w3m for the mac and ended up downloading lynx instead.
lynx –dump gives you very similar results.
Great stuff, it was exactly what I needed for a script I am working on wright now!
see: http://forum.nedlinux.nl/viewtopic.php?pid=354120#p354120
A four year old blog post that STILL sticks out. If only more people had the same approach to the web, the life and everything – “what a wonderful place this would be” !
Thanks.
cURL is a neat tool btw 😉
//MK
I am that person. Thank you so much for this. I didnt want to ask dev of app I use to add this feature. Now I can just change /my/ copy.
Awesome!
this doesn’t work for me. I am trying to pull descriptions of episodes of a TV show but when I use your syntax I am presented with:
>
as if bash is waiting for a terminating symbol
timeless! i wonder if anyone tried this with lynx. @ pete: thnx for the dictionaries and what not!
you can retrieve an html page (with the html stripped off) with lynx as well by using the -dump option. syntax: lynx -dump http://u.rl
just for that person’s information…