It’s been down for a few months, but we’re back again. Hooray!
I mostly blog over at Cucumber nowadays, with the occasional dabble with Medium and quite a bit of Twittering.
Matt Wynne taking it one tea at a time
It’s been down for a few months, but we’re back again. Hooray!
I mostly blog over at Cucumber nowadays, with the occasional dabble with Medium and quite a bit of Twittering.
I’m delighted to announce that I’ll be joining Sandi Metz to teach two courses on Object-Oriented design this summer in London. We’re nick-naming it POODL.
You have two options:

Sandi is not only one of the most experienced object thinkers I know, she’s also a wonderful teacher. If you’ve read her book, Practial Object Oriented Design in Ruby, you’ll already know her knack of bringing scary-sounding design principles gently down to earth with simple, practical examples.
POODL is definitely not just for Rubyists. We’ll teach the examples in Ruby, but any programmer familiar with an Object-Oriented language will be absolutely fine. The challenging stuff will be learning the trade-offs between different design patterns, and how to refactor between them.
The feedback from this course in the US has been amazing, and I’m really looking forward to being a part of it over here in Europe.
BDD is powerful stuff, and it’s much more powerful when your product owner understands the benefits.
We love having product owners at BDD Kickstart. The first day is all about the collaborative aspects of BDD where we learn how to break down and describe requirements using examples. We find that product owners really enjoy it.
That’s why we’re announcing a special promotion for our next public course in London. Use the discount code “BYPO” when booking your three-day ticket, and we’ll throw in a free ticket worth £450 that you can use to bring your product owner, project manager or scrum-master along to day one.
These tickets are limited, so book now before they sell out.
I think balance is important. Whenever I teach people about BDD or automated testing, we make a list of the costs and benefits of test automation.
The lists typically look something like this:
Benefits:
Costs:
The benefits are great, but don’t underestimate the costs. If your team are in the early stages of adopting test automation, you’re going to invest a lot of time in learning how to do it well. You’ll make some mistakes and end up with tests that are hard to maintain.
Even once you’re proficient, it’s important for each test to justify its existence in your test suite. Does it provide enough of a benefit to justify the investment needed to write it, and the ongoing maintenance cost? Is there a way to bring down the ongoing cost, for example by making it faster?
I also find that listing costs and benefits helps to tackle skepticism. Having a balanced discussion makes space for everyone’s point of view.
I’m teaching a public BDD course in London, 4-6 December. If you’d like to take part you can sign up here:
After months of hard work, we’ve got Cucumber 2.0 into a state where it can run its own tests and (usually) give us useful feedback. We’ve just merged this code into the master branch.
There’s still a lot to do. The specs all pass, but only approximately 50 / 150 scenarios are passing. The 100 that fail are tagged out with @wip-new-core while we get them into a passing state.
The decision to move this code into master was taken because we’ve been getting pull requests from kind people fixing things on code that’s going to be deleted for the 2.0 release. Having the 2.0 code on the master branch should help avoid this confusion.
We’ll continue to release bugfixes as needed off of the 1.3.x-bugfix branch, but we’ll concentrate our efforts on getting the 2.0 code ready.
I’d love some more help with this. Particularly:
Helping with (1) could be as simple as taking an individual @wip scenario, diagnosing the root cause, and creating a PR with the @wip tag removed (so that the test is failing) and explaining what needs to be changed. Even if you don’t feel confident to make the change, just doing the work to turn a statistic into a meaningful task on our todo list would be really helpful.
Of course if you want to try and fix the code to make the scenario pass, that would be even better! We’re always happy to give you some free BDD coaching.
I just got back from Baruco. I had a wonderful time, made new friends and caught up with some old ones. but I was still left with a concern. That’s what this post is about.
The whole event felt very professional and well-run. Many of the speakers were people who I recognised or knew from the Ruby community, and I was excited to see what they had to say. The talks varied from heavily technical to very non-technical, and each speaker was well-prepared and delivered their talk in an engaging way. We also had a first-rate MC in the guise of Dr. Nic Williams. The promotional video was brilliant, and the space theme ran on into the conference, with a really theatrical beginning to the conference: the sounds of a rocket-launch, dry ice and Dr. Nic coming on-stage in a full space suit.
As a speaker, I was treated incredibly well. The Codegram staff were just lovely, and checked with me several times a day whether I was OK, if I needed anything. We had our own private room where we could go to chill out away from the crowds. I had free drinks all night long at the parties.
So what am I complaining about?
Well, let me get this straight first. I’m not complaining about Baruco itself. I can’t imagine a nicer bunch of people than the Codegram team, doing a better job of a conference in this single-track, speaker-to-audience format. It’s the format that leaves me uncomfortable.
This format, where big names deliver polished talks to a large audience, seems to be incredibly popular in the Ruby community, yet means that most of the people who attend hardly participate at all. Yes, there are Q&A after the talks and yes, there is usually a slot for lightning talks, but it’s often put towards the bottom of the bill, or sidelined into an evening slot. Mostly, you just turn up and consume ideas from the people on the stage.
This, to me, defeats the primary purpose of a conference. If we just turn up and listen, when do we get a chance to think for ourselves? How do we make new friends when we’re spending so much time in a darkened theatre?
I think that a straight speaker-audience format conference promotes a hero or rock-star culture within the Ruby community, and I think that rock-star culture is poisonous.
I’d like to see our Ruby conferences be much more level playing fields, where we really feel like a community coming together.
Some specific things I’d like to see a lot more of from our conference organisers:
Instead of just talks, let’s have a mix of talks and hands-on sessions. Hands-on sessions give you a chance to experience a new idea instead of just hearing about it. Plus you get to make friends with the people sitting next to you by doing something you both have in common: playing with Ruby.
I’ve been to lots of open-spaces (sometimes called unconferences) and even run a couple myself. What I think is so wonderful about this format is that you can come up with conference content during the conference so if you’re inspired to hack on or discuss something, you can find some like minds to join up with.
I think you need planned, scheduled talks to give a conference some structure and to inspire people, but when the only outlet for spontaneity is lightning talks or hallway cliques, it limits the life of the conference. Don’t make open-space an afterthought: give it equal prominence with the planned parts of the schedule.
Free booze is one way to help people make new friends, but there are others.
Mealtimes are a good time for conversation, so having sit-down meals planned into the conference is great. Interactive workshops and hands-on sessions, as I’ve mentioned, give people more chance to get to know each other. I’ve also been to conferences where they deliberately matched up new attendees with old timers, so that the newbies had a friend from day one. I notice that GoRuCo does this, so kudos to them.
You’ll notice I haven’t included anything in this list about the selection process. I think enough has been said about that already, particularly by the good people of Ruby Manor, Nordic Ruby and Jez Humble of FlowCon. I’m making a wider point about the format, and the spirit of the conference scene.
Let’s stop promoting heroes within our community and make our conferences be more egalitarian, more exploratory, more fun.
This is the pitch that I give right at the beginning of my BDD Kickstart classes to give everyone an overview of what BDD is, and why I think it matters.
In this video, I cover:
If you’d like to learn more, there are still a few tickets left for the next public course in Barcelona on 11th September 2013.
Transitioning to agile is hard. I don’t think enough people are honest about this.
The other week I went to see a team at a company. This team are incredibly typical of the teams I go to see at the moment. They’d adopted the basic agile practices from a ScrumMaster course, and then coasted along for a couple of years. Here’s the practices I saw in action:
This is where it started to fall down. This team have no handle on their velocity. It seems to vary wildly from sprint to sprint, and the elephant in the room is that it’s steadily dropping.
I see this a lot. Even where the velocity appears to be steady, it’s often because the team have been gradually inflating their estimates as time has gone on. They do this without noticing, because it genuinely is getting harder and harder to add the same amount of functionality to the code.
Why? Sadly, the easiest bits of agile are not enough on their own.
Let’s have a look at what the team are not doing:
All of these practices are focussed on keeping the quality of the code high, keeping it malleable, and ultimately keeping your velocity under control in the long term.
Yet most agile teams, don’t do nearly enough of them. My view is that product owners should demand refactoring, just as the owner of a restaurant would demand their staff kept a clean kitchen. Most of the product owners I meet don’t know the meaning of the term, let alone the business benefit.
So why does this happen?
Firstly, everyone on the team needs to understand what these practices are, and how they benefit the business. Without this buy-in from the whole team, it’s a rare developer who has the brass neck to invest enough time in writing tests and refactoring. Especially since these practices are largely invisible to anyone who doesn’t actually read the code.
On top of this, techniques like TDD do –despite the hype– slow a team down initially, as they climb the learning curve. It takes courage, investment, and a bit of faith to push your team up this learning curve. Many teams take one look at it and decide not to bother.
The dirty secret is that without these technical practices, your agile adoption is hollow. Sure, your short iterations and your velocity give you finer control over scope, but you’re still investing huge amounts of money having people write code that will ultimately have to be thrown away and re-written because it can no longer be maintained.
Like any investment decision, there’s a trade-off. Time and money spent helping developers learn skills like TDD and refactoring is time and money that could be spent paying them to build new features. If those features are urgently needed, then it may be the right choice in the short term to forgo the quality and knock them out quickly. If everyone is truly aware of the choice you’re making, and the consequences of it, I think there are situations where this is acceptable.
In my experience though, it’s far more common to see teams sleep-walking into this situation without having really attempted the alternative. If you recognise this as a problem on your team, take the time to explain to everyone what the business benefits of refactoring are. Ask them: would you throw a dinner party every night without doing the washing up?
Does the world need to hear this message? Vote for this article on Hacker News
Refactoring is probably the main benefit of doing TDD. Without refactoring, your codebase degrades, accumulates technical debt, and eventually has to be thrown away and rewritten. But how much refactoring is enough? How do you know when to stop and get back to adding new features?
(image credit: Nat Pryce)
I get asked this question a lot when I’m coaching people who are new to TDD. My answers in the past have been pretty wooly. Refactoring is something I do by feel. I rely on my experience and instincts to tell me when I’m satisfied with the design in the codebase and feel comfortable with adding more complexity again.
Some people rely heavily on metrics to guide their refactoring. I like the signals I get from metrics, alerting me to problems with a design that I might not have noticed, but I’ll never blindly follow their advice. I can’t imagine metrics ever replacing my design intuition.
So how can I give TDD newbies some clear advice to follow? The advice I’ve been giving them up to now has been this:
There are plenty of codebases that suffer from too little refactoring but not many that suffer from too much. If you’re not sure whether you’re doing enough refactoring, you’re probably not.
I think this is a good general rule, but I’d like something more concrete. So today I did some research.
This summer my main coding project has been to re-write the guts of Cucumber. Steve Tooke and I have been pairing on a brand new gem, cucumber-core that will become the inner hexagon of Cucumber v2.0. We’ve imported some code from the existing project, but the majority is brand new code. We use spikes sometimes, but all the code in the master branch has been written test-first. We generally make small, frequent, commits and we’ve been refactoring as much as we can.
There are 160 commits in the codebase. How can I look back over those and work out which ones were refactoring commits?
My first thought was to use git log --dirstat which shows where your commit has changed files. If the commit doesn’t change the tests, it must be a refactoring commit.
Of the 160 commits in the codebase, 58 of them don’t touch the specs. Because we drive all our changes from tests, I’m confident that each of these must be a refactoring commit. So based on this measure alone, at least 36% of all the commits in our codebase are refactorings.
Sometimes though, refactorings (renaming something, for example) will legitimately need to change the tests too. How can we identify those commits?
One obvious way is to look at the commit message. It turns out that a further 11 (or 7%) of the commits in our codebase contained the word ‘refactor’. Now we know that at least 43% of our commits are refactorings.
This still didn’t feel like enough. My instinct is that most of our commits are refactorings.
One other indication of a refactoring is that the commit doesn’t increase the number of tests. Sure, it’s possible that you change behaviour by swapping one test for another one, but this is pretty unlikely. In the main, adding new features will mean adding new tests.
So to measure this I extended my script to go back over each commit that hadn’t already been identified as a refactoring, check out the code and run the tests. I then did the same for the previous commit, and compared the results. All the tests had to pass, otherwise it didn’t count as a refactoring. If the number of passing tests was unchanged, I counted it as a refactoring.
Here are the results now:
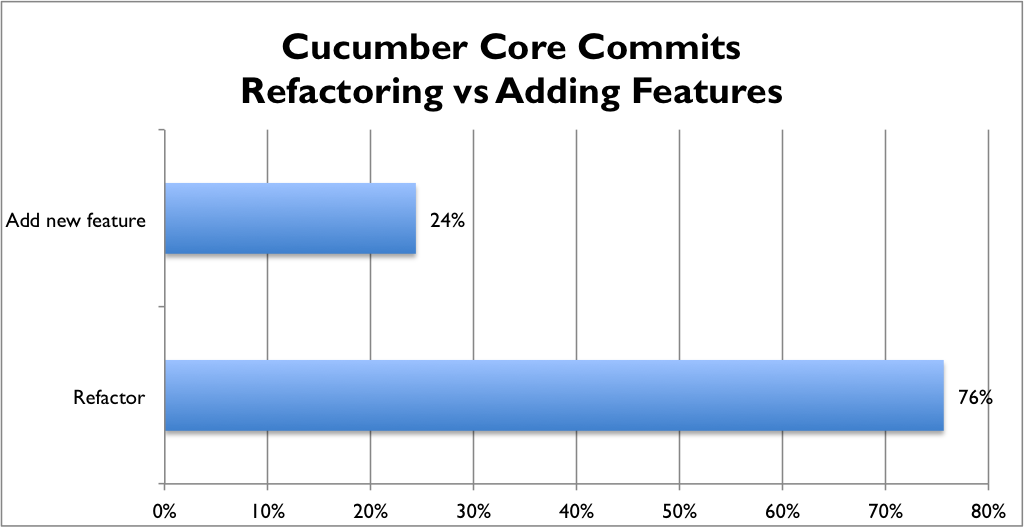
Wow. So according to this new rule, less than 25% of the commits to our codebase have added features. The rest have been either improving the design, or perhaps improvements to the build infrastructure. That feels about right from my memory of our work on the code, but it’s still quite amazing to see the chart.
It looks as though in this codebase, there are about three refactoring commits for every one that adds new behaviour.
There will be some errors in how I’ve collected the data, and I may have made some invalid assumptions about what does or does not constitute a refactoring commit. It’s also possible that this number is artificially high because this is a new codebase, but I’m not so sure about that. We know the Cucumber domain pretty well at this stage, but we are being extremely rigorous to pay down technical debt as soon as we spot it.
We have no commercial pressure on us, so we can take our time and do our best to ensure the design is ready before forcing it to absorb more complexity.
If you’re interested, here’s the script I used to analyse my git repo. I realise it’s a cliche to end your blog post with a question, but I’d love to hear how this figure of 3:1 compares to anything you can mine from your own codebases.
Update 28 July 2013: Corrected ratio from 4:1 to 3:1 – thanks Mike for pointing out my poor maths!
When I run workshops to review and improve people’s automated tests, a common problem I see is the use of sleeps.
I have a simple rule about sleeps: I might use them to diagnose a race condition, but I never check them into source control.
This blog post will look at what it means to use sleeps, why people do it, why they shouldn’t, and what the alternatives are.
If you don’t have time to read this whole article, you can sum it up with this quote from Martin Fowler’s excellent essay on the subject:
Never use bare sleeps to wait for asynchonous responses: use a callback or polling.
— MartinFowler.com
When two code paths run in parallel and then meet at a certain point, you have what’s called a race condition. For example, imagine you’re testing the AJAX behaviour of Google Search. Your test says something like this:
Given I am on the google homepage
When I type "matt" into the search box
Then I should see a list of results
And the wikipedia page for Matt Damon should be the top result
Notice that I didn’t hit Enter in the test, so the results we’re looking for in the two Then steps will be populated by asynchronous javascript calls. As soon as the tests have finished typing “Matt” into the search box, we have a race on our hands: will the app be able to return and populate the results before the tests examine the page to see if the right results are there?
We don’t need this kind of excitement in automated tests. They need to be deterministic, and behave exactly the same way each time they’re run.
The easy route to achieve this is to handicap the tests so that they always lose. By adding a sleep into the test, we can give the app sufficient time to fetch the results, and everything is good.
Given I am on the google homepage
When I type "matt" into the search box
And I wait for 3 seconds
Then I should see a list of results
And the wikipedia page for Matt Damon should be the top result
Of course in practice you’d push this sleep down into step definitions, but you get the point.
So why is this a bad idea?
Sleeps quickly add up. When you use sleeps, you normally have to pad out the delay to a large number of seconds to give you confidence that the test will pass reliably, even when the system is having a slow day.
This means that most of the time, your tests will be sleeping unnecessarily. The system has already got into the state you want, but the tests are hanging around for a fixed amount of time.
All this means you have to wait longer for feedback. Slow tests are boring tests, and boring tests are no fun to work with.
The goal is to minimise the time you waste waiting for the system to get into the right state. As soon as it reaches the desired state, you want to move on with the next step of your test. There are two ways to achieve that:
Using events is great when you can. You don’t need to use some fancy AMQP setup though; this can be a simple as touching a known file on the filesystem which the tests are polling for. Anything to give a signal to the tests that the synchronisation point has been reached. Using events has the advantage that you waste absolutely no time – as soon as the system is ready, the tests are notified and they’re off again.
In many situations though, polling is a more pragmatic option. This does involve the use of sleeps, but only a very short one, in a loop where you poll for changes in the system. As soon as the system reaches the desired state, you break out of the loop and move on.
Many people using Capybara for web automation don’t realise how sophisticated it is for solving this problem.
For example, if you ask Capybara to find an element, it will automatically poll the page if it can’t find the element right away:
find('.results') # will poll for 5 seconds until this element appears
After five seconds, if the element hasn’t appeared, Capybara will raise an error. So your tests won’t get stuck forever.
This also works with assertions on Capybara’s page object:
page.should have_css('.results')
Similarly, if you want to wait for something to disappear before moving on, you can tell Capybara like this:
page.should have_no_css('.loading')
The reason you need to use should have_no_css here, rather than should_not have_css is because the have_no_css matcher is going to deliberately poll the page until the thing disappears. Think about what will happen if you use the have_css matcher instead, even with a negative assertion.
As Jonas explained, there used to be a wait_until method on Capybara’s API, but it was removed. It’s easy enough to roll your own, but you can also use a library like anticipate if you’d rather not reinvent the wheel.