Refactoring is probably the main benefit of doing TDD. Without refactoring, your codebase degrades, accumulates technical debt, and eventually has to be thrown away and rewritten. But how much refactoring is enough? How do you know when to stop and get back to adding new features?
(image credit: Nat Pryce)
I get asked this question a lot when I’m coaching people who are new to TDD. My answers in the past have been pretty wooly. Refactoring is something I do by feel. I rely on my experience and instincts to tell me when I’m satisfied with the design in the codebase and feel comfortable with adding more complexity again.
Some people rely heavily on metrics to guide their refactoring. I like the signals I get from metrics, alerting me to problems with a design that I might not have noticed, but I’ll never blindly follow their advice. I can’t imagine metrics ever replacing my design intuition.
So how can I give TDD newbies some clear advice to follow? The advice I’ve been giving them up to now has been this:
There are plenty of codebases that suffer from too little refactoring but not many that suffer from too much. If you’re not sure whether you’re doing enough refactoring, you’re probably not.
I think this is a good general rule, but I’d like something more concrete. So today I did some research.
Cucumber’s new Core
This summer my main coding project has been to re-write the guts of Cucumber. Steve Tooke and I have been pairing on a brand new gem, cucumber-core that will become the inner hexagon of Cucumber v2.0. We’ve imported some code from the existing project, but the majority is brand new code. We use spikes sometimes, but all the code in the master branch has been written test-first. We generally make small, frequent, commits and we’ve been refactoring as much as we can.
There are 160 commits in the codebase. How can I look back over those and work out which ones were refactoring commits?
Git log
My first thought was to use git log --dirstat which shows where your commit has changed files. If the commit doesn’t change the tests, it must be a refactoring commit.
Of the 160 commits in the codebase, 58 of them don’t touch the specs. Because we drive all our changes from tests, I’m confident that each of these must be a refactoring commit. So based on this measure alone, at least 36% of all the commits in our codebase are refactorings.
Sometimes though, refactorings (renaming something, for example) will legitimately need to change the tests too. How can we identify those commits?
Commit message
One obvious way is to look at the commit message. It turns out that a further 11 (or 7%) of the commits in our codebase contained the word ‘refactor’. Now we know that at least 43% of our commits are refactorings.
This still didn’t feel like enough. My instinct is that most of our commits are refactorings.
Running tests
One other indication of a refactoring is that the commit doesn’t increase the number of tests. Sure, it’s possible that you change behaviour by swapping one test for another one, but this is pretty unlikely. In the main, adding new features will mean adding new tests.
So to measure this I extended my script to go back over each commit that hadn’t already been identified as a refactoring, check out the code and run the tests. I then did the same for the previous commit, and compared the results. All the tests had to pass, otherwise it didn’t count as a refactoring. If the number of passing tests was unchanged, I counted it as a refactoring.
Here are the results now:
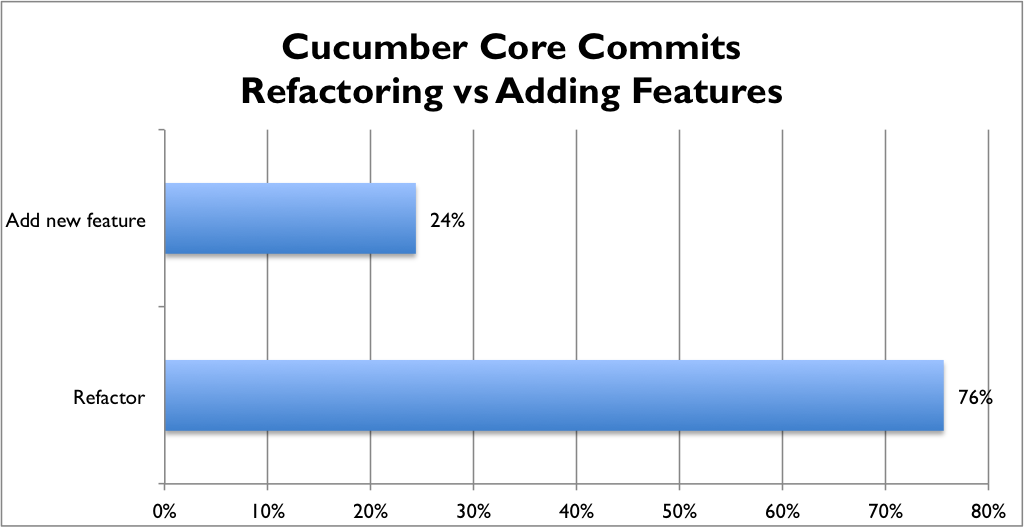
Wow. So according to this new rule, less than 25% of the commits to our codebase have added features. The rest have been either improving the design, or perhaps improvements to the build infrastructure. That feels about right from my memory of our work on the code, but it’s still quite amazing to see the chart.
Conclusions
It looks as though in this codebase, there are about three refactoring commits for every one that adds new behaviour.
There will be some errors in how I’ve collected the data, and I may have made some invalid assumptions about what does or does not constitute a refactoring commit. It’s also possible that this number is artificially high because this is a new codebase, but I’m not so sure about that. We know the Cucumber domain pretty well at this stage, but we are being extremely rigorous to pay down technical debt as soon as we spot it.
We have no commercial pressure on us, so we can take our time and do our best to ensure the design is ready before forcing it to absorb more complexity.
If you’re interested, here’s the script I used to analyse my git repo. I realise it’s a cliche to end your blog post with a question, but I’d love to hear how this figure of 3:1 compares to anything you can mine from your own codebases.
Update 28 July 2013: Corrected ratio from 4:1 to 3:1 – thanks Mike for pointing out my poor maths!
This is great insight, Matt!
It makes me think of this http://www.infoq.com/presentations/Technical-Debt-Process-Culture;jsessionid=EA22BC6DF3B87E9E7C75DC9773887074 which talks about the cost of not spending the time on refactoring.
Umm, 76:24 is closer to 3:1! Which feels about right.
Yeah 3:1 Matt!
Ummm dare i say it but does this raise an argument to do more thinking/design upfront?!
can you drill into a few of the refactors and see if they would or wouldn’t have been captured earlier?
It’d be a shame to think you’re in a product innovation team and 3/4 of your time is refactoring, no?
I’ve been reading around and found some good discussions on design within agile by @scottwambler and @simonbrown