How important is it to measure how long something took?
Well, so the received wisdom goes, by comparing how long it took you to complete your a task against the estimate you made before starting it, you get an idea of how good your estimate was. So far, so good.
But what if your estimate turned out to be wrong? What are you going to do about that?
One of the culture shocks I think scrum introduces it the idea that we almost always just look forward. I don’t care how long you’ve spent on a task, I just want to know how long you think it will take you to finish it, based on what you know right now.
Tomorrow, if you turned out to be wrong, that’s OK. All we need to know is how much longer it’s going to take to get it done.
Except it’s not OK.
Because if your task, which you originally estimated would take 2 hours has taken you two days, and it’s still not done, then something is impeding you.
Fortunately in a team practicing scrum, we have a daily 15-minute meeting where impediments like this are made visible to the entire team, and someone takes away the action to resolve the impediment.
Rather than having to retrospectively scan reports of esimates vs actuals in a spreadsheet, the problem can be highlighted as it’s happening, and hopefully resolved.
Agile teams also have a second line of defence against more stubborn impediments: The retrospective.
With these two facilities in place, it becomes unnecesary to track the details of estimates vs actuals. The administrative overhead on developers is reduced, and they can get back to writing solid code.
Some people find this difficult to accept – there’s a familiarity to the recording of the numbers. We’ve allways done it. It makes me feel safe. Somebody will ask us for them.
If someobody asks you how good your estimating is – show them your burn-down chart.
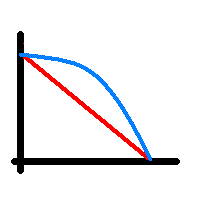
It’s bloody obvious from the shape of the chart if your estimating is any good. And if they want figures, measure the difference in area beneath your real curve (blue line) and your ‘ideal’ diagonal curve (red line). Every hour above the diagnoal line is an under-estimated hour. Show this to your team. Get them to look at it and reflect on how realistic they’re being when they estimate tasks.
If somebody asks you why your estimates were too low – listen to people. Look at your impediments log, and the write-up of your retrospectives. You need a culture where impediments get surfaced quickly from the team, where it’s OK to say things aren’t going well, and where problems raised get solved and cleared out of the way.